Overview
I’m teaching a partial differential equations (PDEs) course in the mathematics department at the moment. A typical ‘gimme’ question for assignments and tests is to get the students to classify a given equation as linear or nonlinear (most of the theory we develop in the course is for linear equations so we need to know what this means). Since we aim to introduce the students to a bit of operator theory we often switch back and forward between talking about linear/nonlinear PDEs and linear/nonlinear operators.
One of the students noticed that this introduced some ambiguity into our classification problem and asked a great question. I think it illustrates a useful general point about terminology like linear vs nonlinear and how these terms can be misleading or ambiguous. So here’s the question and my attempt at clarifying the ambiguity.
The question
It’s my understanding that a PDE is linear if we can write it in the form 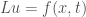
If we are given a PDE that looks like 
For example the operator A defined by

is not a linear differential operator. However the equation Au = 0 is the same as 

So (I believe I’m correct in saying this), the original PDE is linear, because it can be rewritten in this form Lu = f(x,t) for some linear differential operator L and function f(x,t).
My question is what sort of working are we expected to show, if we aim to prove the PDE Au=0 is not linear? For the purposes of the assignment does it suffice to prove that A is not linear?
My response
Here was my response and attempt to clarify (corrections/comments welcome!).
Great question!
As you’ve noticed there is some ambiguity when we move back and forward between talking about equations and operators. This is to be expected since a function (e.g. an operator) is a different type of mathematical object to an equation.
For example the function 

You’ve correctly noticed that if we can write a differential equation as Lu = f where L is some linear operator then the differential equation is also called linear. Unfortunately, again as you’ve noticed, this definition makes it hard to decide when an equation is nonlinear as you may be able to write a linear equation in terms of a nonlinear operator with the right choice of f. This is because the negation of ‘there exists’ a linear operator is ‘there doesn’t exist a linear operator’.
So proving that an equation is linear is easy using the operator definition – we just find any linear operator that works.
On the other hand, proving that an equation is nonlinear is harder using this definition – it would require showing all operators for which Au = f are nonlinear.
This seems too hard to do directly, so let’s reformulate it in an equivalent but easier-to-use way.
We want to keep our definitions of linear and nonlinear as close as possible for the two cases of operators and equations.
So, how about:
Improved definitions
An operator acting on u is linear iff L(au+bv) = aL(u) + bL(v) for any u and v in the operator’s domain and constants a, b.
and
Given an equation written in the from Au = f for some operator A and forcing function f, the equation is linear iff A(au+bv) = aA(u) + bA(v) for any two solutions u, v to the equation Au = f.
I think this definition should cover your example (try it! Note that it is slightly subtle how this makes a difference! But, basically, we get to use the f = 0 in the equation case now).
Also note that:
The function definition now explicitly talks about linearity with respect to how it operates on objects in its domain while the equation definition talks explicitly about behaviour with respect to solutions to that equation. This seems natural given the different ‘nature’ of ‘functions’ and ‘equations’.
Does that make sense?
Morally speaking
I think the broader lesson is that terms like linear/nonlinear are relative to the specific mathematical representation chosen and how we interact with that representation. A ‘system’ is not really intrinsically linear or nonlinear, rather an ‘action’ (or function or operator or process) is linear or nonlinear with respect to a specific set of ‘objects’ or ‘measurements’ or ‘perturbations’ or whatever. This needs to be made explicit for an unambiguous classification to be carried out.
Generalisation
Perhaps generalising too far, something like this came up in some recent ‘philosophical’ discussions I’ve been having over at Mayo’s blog (and was also at the heart of another scientific disagreement I once had with an experimentalist about interpreting aquaporin knockout experiments…).
For example, it has been pointed out that while ‘chaos’ is typically associated with (usually finite-dimensional) nonlinear systems, there are examples of infinite-dimensional linear systems that exhibit all the hallmarks of chaos – see e.g. ‘Linear vs nonlinear and infinite vs finite: An interpretation of chaos‘ by Protopopescu for just one example. So, changing the underlying ‘objects’ used in the representation changes the classification as ‘linear’ or ‘nonlinear’ or, as Protopopescu states
Linear and nonlinear are somewhat interchangeable features, depending on scale and representation…chaotic behavior occurs… when we have to deal with infinite amounts of information at a finite level of operability. In this sense, even the most deterministic system will behave stochastically due to unavoidable and unknown truncations of information.
This theme appears again and again at various levels of abstraction – e.g. we saw it in a high-school math problem where a singularity (a type of ‘lack of regularity’) arose (which we interpreted as) due to an incompatibility between a regular higher-dimensional system and a constraint restricting that system to a lower-dimensional space. (Compare the abstract operator itself with the operator + equating it to zero to get an equation.) We were faced with the choice of a regular but underdetermined system that required additional information for a unique solution or a ‘unique’ but singular (effectively overdetermined) system. Similarly other ‘irregular’ behaviour like ‘irreversibility’ can often be thought of as arising due to a combination of ‘reversible’ (symmetric/regular etc) microscopic laws + asymmetric boundary conditions/incomplete measurement constraints. Similar connections between ‘low/high dimensional’ systems and ‘stable/unstable’ systems are discussed by Kuehn in ‘The curse of instability‘.
To me this presents a helpful heuristic decomposition of models of the world into two-level decompositions like ‘irregular nature’ -> ‘regular, high-dimensional nature’ + ‘limited accessibility to nature’ (h/t Plato) or ‘internal dynamics’ + ‘boundary conditions’, ‘reversible laws’ + ‘irreversible reductions/coarse-graining’ etc. Note also that, on this view, ‘infinite’ and ‘finite’ are effectively ‘relative’, ‘structural’ concepts – if our ‘access’ to the ‘real world’ is always and instrinsically limited it leads us to perceive the world as effectively infinite (in some sense) regardless of whether the world is ‘actually’ infinite. You still can’t really avoid ‘structural infinities’ – e.g. continuous transformations – though.
It seems clear that this also inevitably introduces ‘measurement problems’ that aren’t that dissimilar to those considered to be intrinsic to quantum mechanics into even ‘classical’ systems, and leads to ideas like conceiving of ‘stochastic’ models as ‘chaotic deterministic’ systems and vice-versa.