Overview
A short, sketchy and somewhat reluctant note on p-values.
What are p-values for?
One of the key intended uses of p-values is widely acknowledged to be to ‘avoid mistaking noise for signal’. Let’s call this use one.
A related – but distinct – idea is that they are a measure of ‘evidence’. Let’s call this use two.
Evidence?
Richard Royall is among the well-known critics of p-values as evidential measures. On the other hand, he has also written on the concept of ‘misleading evidence’, which appears closely tied to the first use. The short version of his account is that, rather than a p-value, a likelihood ratio should be used as an evidential measure, but that this can also be misleading in individual cases– e.g. it is possible for a particular experiment or study to produce strong but misleading evidence.
In his case this means: a large likelihood ratio arising by chance in a single study. One would not expect this same likelihood ratio to consistently appear in repeated trials.
Apparent signal
More generally, rather than ‘evidence’ let’s call the summary of a particular trial or experiment (or dataset) the ‘apparent signal’. In the terms of my previous post, this is simply the value of an interesting estimator. You have a dataset and notice something interesting; you then summarise this via a ‘statistic’ of some sort.
Importantly, recall that in the previous post we required two things:
- An interesting summary of the given data, and
- An idea of the stability of this summary with respect to ‘similar’ datasets.
Similarly, Royall in fact does make use of what amounts to p-values for characterising this idea of misleading signal. He shows that for two simple hypotheses labelling two probability model instances (with densities) we have
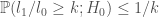
where 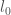
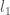
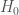
In words: the probability of obtaining an even stronger ‘apparent signal’ (likelihood ratio) under the null model is bounded by the reciprocal of the signal strength (when measuring signal strength in terms of likelihood ratios). This itself is exactly what a p-value is intended to do.
Signal stability vs strength
It appears then that the role of the p-value is best thought of as characterising the stability of the apparent signal rather than the apparent signal itself.
For example, it is perfectly possible to have a strong but unstable apparent signal. This is also known as ‘overfitting’. Or, a weak but stable signal: a small but consistent ‘effect’.
I would argue that the ‘effect estimate’ itself should be used as the ‘evidential’ measure (if such a measure is desired – I have generally come to prefer to think in different terms, but this is the nearest translation I can offer). This is also a natural consequence of Royall’s argument, but separated from dependence on the likelihood ratio.
So, a larger ‘effect estimate’ is itself greater ‘evidence’ against the null. This is also more naturally compatible with ‘approximation’-based thinking (I think!): a larger effect estimate is a greater indication of the inadequacy of the null as a good approximate model.
A key here is the tension between the ‘signal’ component, e.g. the estimated mean value say, and the ‘noise’ component e.g. the variability of this. It is the signal that measures ‘evidence’ (or whatever you want to call it); the variability measures the stability of this.
Measuring apparent signal
If the p-value measures the stability of an apparent signal but not the strength as such, how exactly should we measure strength? As mentioned I think we need to use the ‘effect estimate’ itself (and more generally direct ‘statistics of interest’ calculated from the data) as the natural measures of ‘interestingness’ or ‘signal’. Note though that this requires an idea of ‘how large of an effect is interesting’ independently of its probability under the null.
Royall’s proposal is to report the likelihood ratio between the null and an interesting comparison hypothesis. While I now doubt the generality of the likelihood ratio approach (and likelihood-based approaches in general) this again illustrates the important point: your statistic/estimator/apparent signal measure should reflect what is of interest to the analyst and usually requires more than just a null. In essence this is because a ‘null’ consists of ‘zero signal’ and an assumed ‘noise’ model. We want to know what ‘non-zero signal’ should look like.
Comparative choice dilemma
A big issue is when the problem is framed as having to choose between only two discrete models (i.e. between two simple hypotheses). This raises an issue because it could be the case that neither model is a good fit but one is still a much ‘better’ fit than the other. This is a potential problem for the idea of ‘comparative’ testing/evidence.
In this case one faces a tension: if you use a test statistic or ‘apparent signal’ measure that only compares the null to the data then you may reject it. If you then implicitly embed this into a comparative/two model choice problem then you are automatically ‘accepting the alternative’. But this may itself be a bad model. It could even be a worse model.
One ‘solution’, if you must phrase it as a comparative choice problem, is to include both models in the test statistic itself. This is what is done when the likelihood ratio is used as the test statistic. Thus the likelihood ratio measures the ‘comparative evidence’ or ‘comparative apparent signal’ while the p-value for this likelihood ratio measures the probability of this being a misleading signal.
In short:
- Your statistic captures what you mean by interesting, so anything you are interested in (e.g. alternative hypotheses, effect sizes of interest etc) should be included here. It should be expressed in units of relevance to the problem and this is not generally ‘probability’.
- A p-value is one way of summarising the stability of your statistic of interest, under ‘null variations’. It does not itself measure interestingness.
