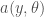Another short (and simple) note on the so-called tacking paradox from the philosophy of science literature. Continuing on from here and related to a recent blog comments exchange here. See those links for the proper background.
[Disclaimer: written quickly and using wordpress latex haphazardly with little regard for aesthetics…]
Consider a scientific theory with two ‘free’ or ‘unknown’ parameters, a and b say. This theory is a function 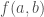 which outputs predictions
which outputs predictions  . I will assume this is a deterministic function for simplicity.
. I will assume this is a deterministic function for simplicity.
Suppose further that each of the parameters is discrete-valued and can take values in 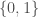 . Assuming that there is no other known constraint (i.e. they are ‘variation independent’ parameters) then the set of possible values is the set of all pairs of the form
. Assuming that there is no other known constraint (i.e. they are ‘variation independent’ parameters) then the set of possible values is the set of all pairs of the form
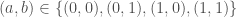
That is, 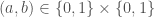 . Just to be simple-minded let’s arrange these possibilities in a matrix giving
. Just to be simple-minded let’s arrange these possibilities in a matrix giving

This leads to a set of predictions for each possibility, again arranged in a matrix
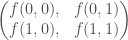
Now our goal is to determine which of these cases are consistent with, supported by and/or confirmed by some given data (measured output) 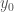 .
.
Suppose we define another function of these two parameters to represent this and call it 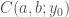 for ‘consistency of’ or, if you are more ambitious, ‘confirmation of’ any particular pair of values
for ‘consistency of’ or, if you are more ambitious, ‘confirmation of’ any particular pair of values 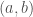 with respect to the observed data .
with respect to the observed data .
For simplicity we will suppose that outputs a definite value which can be definitively compared to the given . We will then require  iff
iff 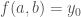 , and
, and 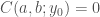 otherwise. That is, it outputs 1 if the predictions given
otherwise. That is, it outputs 1 if the predictions given  and
and  values match, 0 if the predictions do not. Since will be fixed here I will drop , i.e. I will use
values match, 0 if the predictions do not. Since will be fixed here I will drop , i.e. I will use 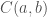 without reference to .
without reference to .
Now suppose that we find the following results for our particular case

How could we interpret this? We could say e.g.  and
and 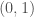 are ‘confirmed/consistent’ (i.e.
are ‘confirmed/consistent’ (i.e.  ), or we could shorten this to say
), or we could shorten this to say  is confirmed for any replacement of the second argument. Clearly this corresponds to a case where the first argument is ‘doing all the work’ in determining whether or not the theory matches observations.
is confirmed for any replacement of the second argument. Clearly this corresponds to a case where the first argument is ‘doing all the work’ in determining whether or not the theory matches observations.
Now the ‘tacking paradox’ argument is essentially:
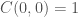
so
is confirmed, i.e. ‘a=0 & b=0’ is confirmed. But ‘a=0 & b=0’ logically implies ‘b=0’ so we should want to say ‘b=0’ is confirmed. But we saw
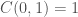
and so
is also confirmed, which under the same reasoning gives that ‘b=1’ is confirmed!
Contradiction!
There are a number of problems with this argument, that I would argue are particularly obscured by the slip into simplistic propositional logic reasoning.
In particular, we started with a clearly defined function of two variables . Now, we found that in our particular case we could reduce some statements involving to an ‘essentially’ one argument expression of the form ‘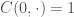 ‘ or ‘ is confirmed’, i.e. we have confirmation for a=0 and b ‘arbitrary’. This is of course just ‘quantifying’ over the second argument – we of course can’t leave any free (c.f. bound) variables. But then we are led to ask
‘ or ‘ is confirmed’, i.e. we have confirmation for a=0 and b ‘arbitrary’. This is of course just ‘quantifying’ over the second argument – we of course can’t leave any free (c.f. bound) variables. But then we are led to ask
What does it mean to say ‘b is confirmed’ in terms of our original givens?
Is this supposed to refer to 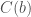 ? But this is undefined –
? But this is undefined –  is of course a function of two variables. Also, b is a free (unbound) variable in this expression. Our previous expression had one fixed and one quantified variable, which is different to having a function of one variable.
is of course a function of two variables. Also, b is a free (unbound) variable in this expression. Our previous expression had one fixed and one quantified variable, which is different to having a function of one variable.
OK – what about trying something similar to the previous case then? That is, what about saying 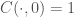 ? But this is a short for a claim that both and
? But this is a short for a claim that both and 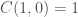 hold (or that their conjunction is confirmed, if you must). This is clearly not true. Similarly for
hold (or that their conjunction is confirmed, if you must). This is clearly not true. Similarly for 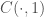 .
.
So we can clearly see that when our theory and hence our ‘confirmation’ function is a function of two variables we can only ‘localise’ when we spot a pattern in the overall configuration, such as our observation that holds.
So, while the values of the C function (i.e. the outputs of 0 and 1) are ordered (or can be assumed to be), this does not guarantee a total order when it is ‘pulled back’ to the parameter space. That is, 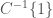 does not guarantee an ordering on the parameter space that doesn’t already admit an ordering! It also doesn’t allow us to magically reduce a function of two variables to a function of one without explicit further assumptions. Without these we are left with ‘free’ (unbound) variables.
does not guarantee an ordering on the parameter space that doesn’t already admit an ordering! It also doesn’t allow us to magically reduce a function of two variables to a function of one without explicit further assumptions. Without these we are left with ‘free’ (unbound) variables.
This is essentially a type error – I take a scientific theory (here) to be a function of the form
 ,
,
i.e a function from a two-dimensional ‘parameter’ (or ‘proposition’) space to a (here) one dimensional ‘data’ (or ‘prediction’, ‘output’ etc) space. The error (or ‘paradox’) occurs when taking a scientific theory to be simply a pair
 ,
,
rather than a function defined on this pair.
That is, the paradox arises from a failure to explicitly specify how the parameters of the theory are to be evaluated against data, i.e. a failure to give a ‘measurement model’.
(Note: Bayesian statistics does of course allow us to reduce a function of two variables to one via marginalisation, and given assumptions on correlations, but this process again illustrates that there is no paradox; see previous posts).
One objection is to say – “well this clearly shows a ‘logic’ of confirmation is impossible”. Staying agnostic with respect to this response, I would instead argue that what it shows is that:
The ‘logic’ of scientific theories cannot be a logic only of ‘one-dimensional’ simple propositions. A scientific theory is described at the very, very minimum by a ‘vector’ of such propositions (i.e. by a vector of parameters), which in turn lead to ‘testable’ predictions (outputs from the theory). That is, scientific theories are specified by multivariable functions. To reduce such functions of collections of propositions, e.g. a function f(a,b) of a pair (a,b) of propositions, to functions of less propositions, e.g. ‘f(a)’, requires the use – again at very, very minimum, of quantifiers over the ‘removed’ variables, e.g. ‘f(a,b) = f(a,-) for all choices of b’.
Normal probability theory (e.g the use of Bayesian statistics) is still a potential candidate in the sense that it extends to the multivariable case and allows function reduction via marginalisation. Similarly, pure likelihood theory involves concepts like profile likelihood to reduce dimension (localise inferences). While standard topics of discussion in the statistical literature (e.g. ‘nuisance parameter elimination’), this all appears to be somewhat overlooked in the philosophical discussions I’ve seen.
So this particular argument is not, to me, a good one against Bayes/Likelihood approaches.
(I am, however, generally sympathetic to the idea that functions like that above are better considered as consistency functions rather than as confirmation functions – in this case the, still fundamentally ill-posed, paradox ‘argument’ is blocked right from the start since it is ‘reasonable’ for both ‘b=0’ and ‘b=1‘ to be consistent with observations. On the other hand it is still not clear how you are supposed to get from a function of two variables to a function of one. Logicians may notice that there are also interesting similarities with intuitionistic/constructive logic see here or here and/or modal logics, see here – I might get around to discussing this in more detail someday…)
To conclude: the slip into the language of simple propositional logic, after starting from a mathematically well-posed problem, allows one to ‘sneak in’ a ‘reduction’ of the parameter space, but leaves us trying to evaluate a mathematically undefined function like  .
.
The tacking ‘paradox’ is thus a ‘non-problem’ caused by unclear language/notation.
Addendum – recently, while searching to see if people have made similar points before, I came across this nice post ‘Probability theory does not extend logic‘.
The basic point is that while probability theory uncontroversially ‘extends’ what I have called simple ‘one-dimensional’ propositional logic here, it does not uncontroversially extend predicate logic (i.e. the basic logical language required for mathematics, which uses quantifiers) nor logic involving relationships between quantities requiring considerations ‘along different dimensions’.
While probability theory can typically be made to ‘play nice’ with predicate logic and other systems of interest it is important to note that it is usually the e.g. predicate logic or functional relationships – basically, the rest of mathematical language – doing the work, not the fact that we replace atomic T/F with real number judgements. Furthermore the formal justifications of probability theory as an extension of logic used in the propositional case do not translate in any straightforward way to these more complicated logical or mathematical systems.
Interestingly for the Cox-Jaynesians, while (R.T.) Cox appears to have been aware of this, and he even considered extensions involving ‘vectors of propositions’ – leading to systems which no longer satisfy all the Boolean logic rules (see e.g. the second chapter of his book) – Jaynes appears to have missed the point (see e.g. Section 1.8.2 of his book). As hinted at above, some of the ambiguities encountered are potentially traceable – or at least translatable – into differences between classical and constructive logic. Jaynes also appears to have misunderstood the key issues here, but again that’s a topic for another day.
Now all of this is not to say that Bayesian statistics as practiced is either right or wrong but that the focus on simple propositional logic is the source of numerous confusions on both sides.
Real science and real applications of probability theory involve much more than ‘one-dimensional’ propositional logic. Addressing these more complex cases involves numerous unsolved problems.
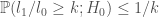
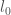 and
and 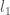 are the likelihoods associated with the respective models and
are the likelihoods associated with the respective models and 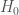 indicates that the probability is calculated under the ‘null’ model labelled by 0.
indicates that the probability is calculated under the ‘null’ model labelled by 0.
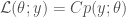
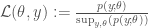

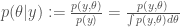
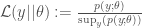
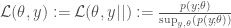
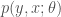
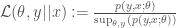
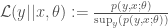
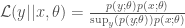
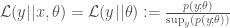

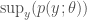
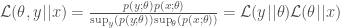

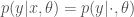

 ,
,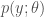
 ,
, 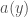 and associated joint or conditional distributions in the usual way(s). The conditional distribution of
and associated joint or conditional distributions in the usual way(s). The conditional distribution of 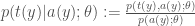 .
.
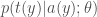 .
.
 and
and 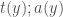 are taken to be distinct then what should the latter be called?
are taken to be distinct then what should the latter be called?
![\mathcal{L}_{a,C} := \begin{cases} p(t(y)| a(y); \theta), \text{ if } p(a(y); \theta) = C, C \in (0,1] \\ 0, \text{ otherwise} \end{cases}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D_%7Ba%2CC%7D+%3A%3D+%5Cbegin%7Bcases%7D+p%28t%28y%29%7C+a%28y%29%3B+%5Ctheta%29%2C+%5Ctext%7B+if+%7D+p%28a%28y%29%3B+%5Ctheta%29+%3D+C%2C+C+%5Cin+%280%2C1%5D+%5C%5C+0%2C+%5Ctext%7B+otherwise%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=444444&s=0&c=20201002)